内容页分页采集
{success} 内容页分页采集功能,就是文章详情页面并不是一页,而是拆分成了多页
{primary} 内容分页采集核心以及实现思想:在当前详情页面。获取详情下一页的url。拿到下一页的内容拼接到第一页的内容结尾。以此循环,结束条件:如果当前页面地址和下一页页面地址一样。及视为完成,或者下一页地址为空及视为完成。
{warning} 分页规则的debug测试重点
-
第一步:务必测试内容第一页,是否能获取到第二页的 地址。
-
第二步:务必测试内容最后一页,要求有两种结果。
- 和最后一页的链接相同(程序判断相同会跳出)
- 获取到的链接为空(程序判断跳出)实现这两个就ok拉
例子一
http://www.xigushi.com/xygs/14167.html

目的要拿到下一页的链接
规则 .page a:contains(下一页)
还能怎么写?
.page>ul>li>a:contains(下一页)
...
:contains() 这个语法是指:匹配某标签文本中包含 下一页 文本的节点。可查看jquery文档{info} 配置中心点击导入默认例子。可以导入这个配置哦。
{warning} 程序小提示。分页循环采集最大次数50次,就跳出不再继续采集循环采集详情页,原因1 鼠友规则写的不规范,掉入死循环就完蛋了。原因2:正常详情页分页很少有超过50分页,
例子二
http://www.qigushi.com/tonghuagushi/3650.html
 还有这种类型的麻烦一点,没有文本 连 > 这个符号都是js加载的
还有这种类型的麻烦一点,没有文本 连 > 这个符号都是js加载的
既然无法定位到 > 那我们就定位当前页码,通过当前页码找到下一页页码
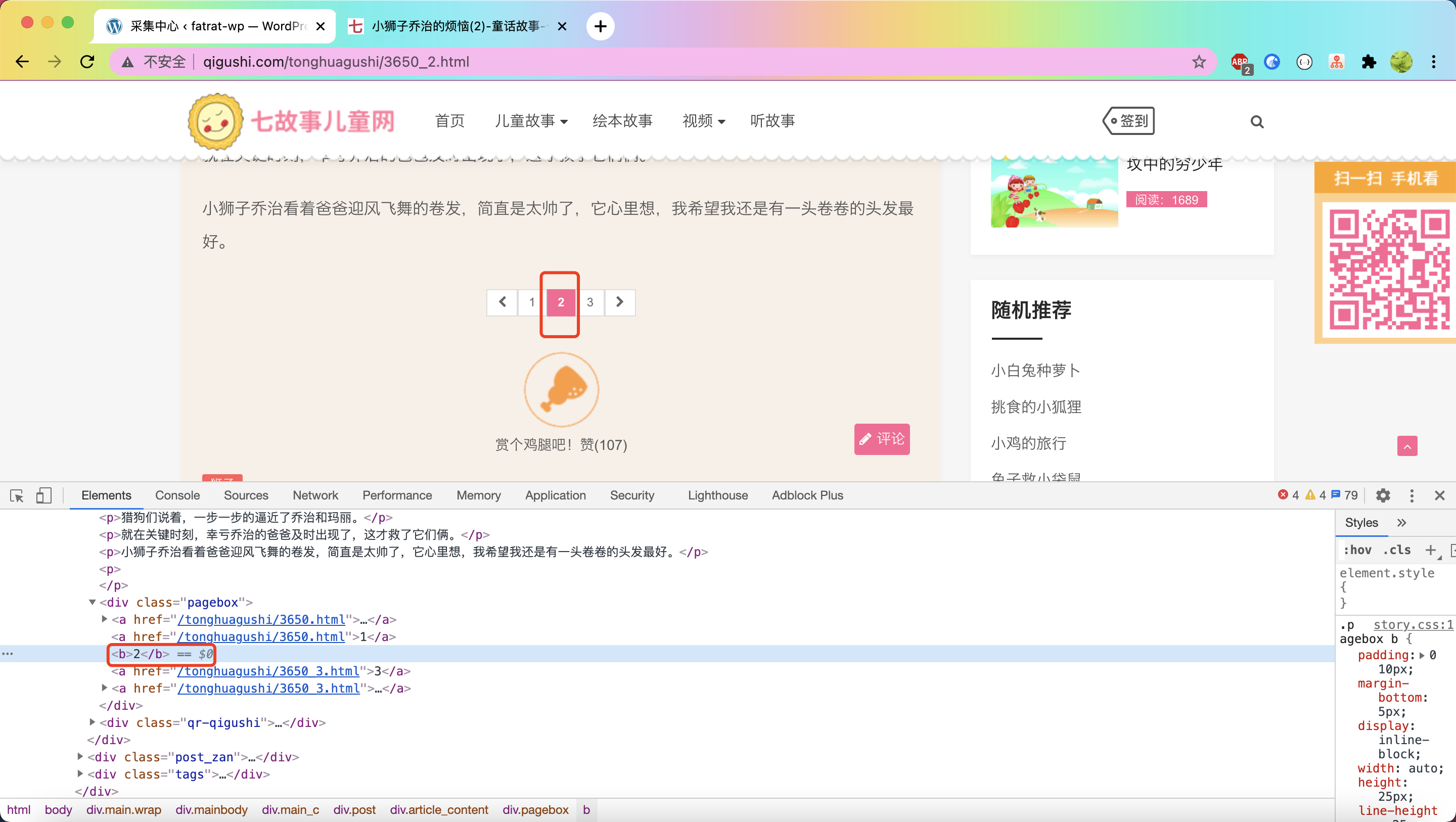
首先我们定位 b标签
规则:.pagebox>b
下一步定位b后面兄弟节点 a
规则:.pagebox>b+a
意思就是 选择b后面的兄弟节点 a,这样就定位到了a(即是下一页的url)
测试结果
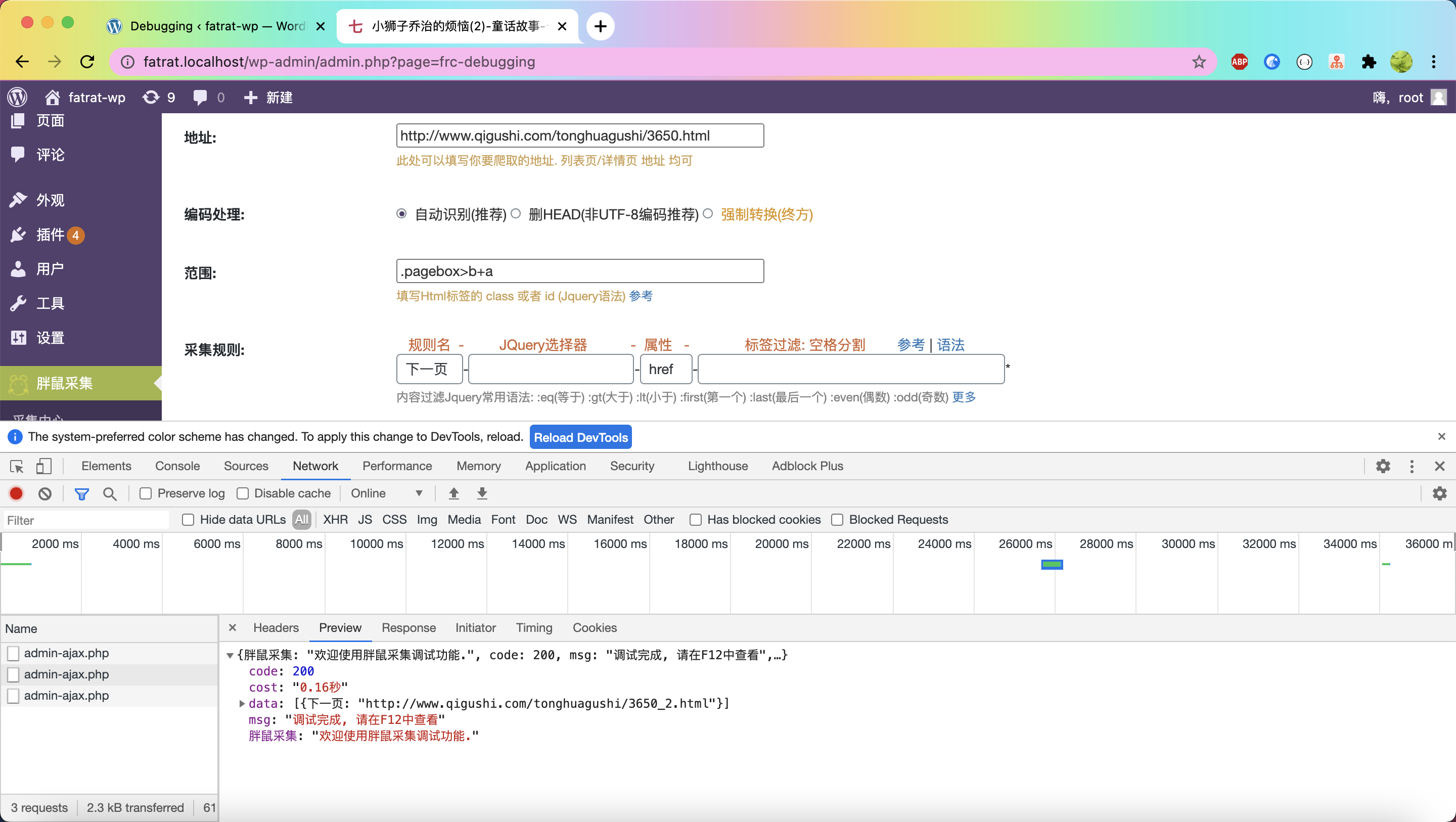
{success} 更多例子会逐步完善。也欢迎鼠友贡献一些奇特的例子。有问题记得在群内讨论哦