创建一个列表采集规则教程
{primary} 通过简单学习掌握爬虫技巧是胖鼠采集的核心
![]()
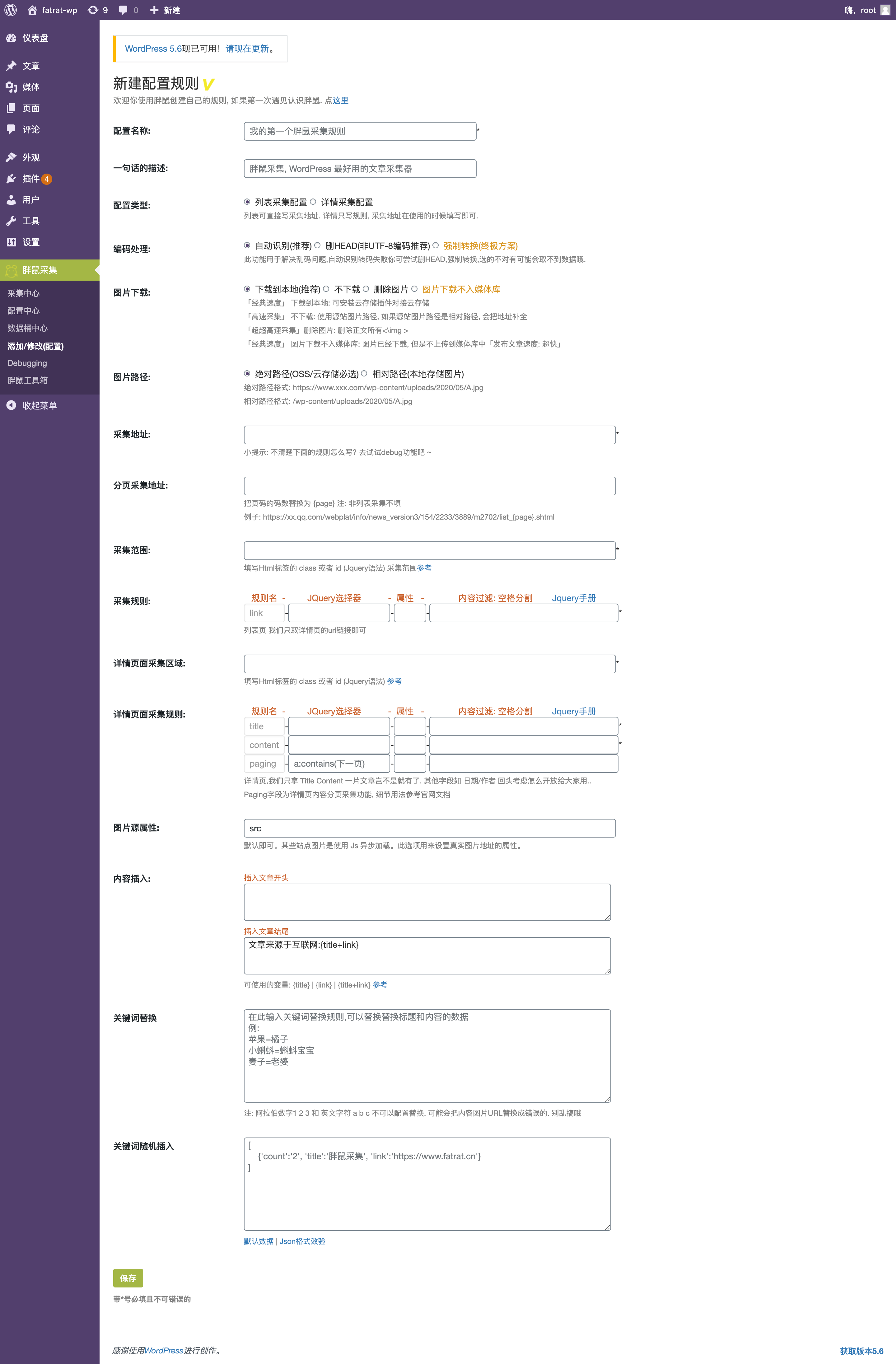
必填配置介绍
| 必填配置介绍 | 描述 |
|---|---|
| 采集地址 | 采集地址 |
| 采集范围 | 采集范围的选择,决定列表采集是否成功 |
| 采集规则 | Jquery一般填a 属性href 注意:如果在采集范围中已经定位到a标签这里可以留空 |
| 详情页采集区域 | 包含住你想要的数据块即可 |
| 详情页采集规则 | Title Content 两个字段为必填项 两个字段必须都获取到数据才能采集成功 |
{success} 下图中输入框后标星为必填项。
{info} Jquery选择器 id是#号 class是. 一定不要落下哦
我下面的例子中每个选择器都有 . 或者 # 大家放大图仔细看
寻仙例子
目标采集目标地址: 这是国内某游戏新闻列表页 //xx.qq.com/webplat/info/news_version3/154/2233/3889/m2702/list_1.shtml
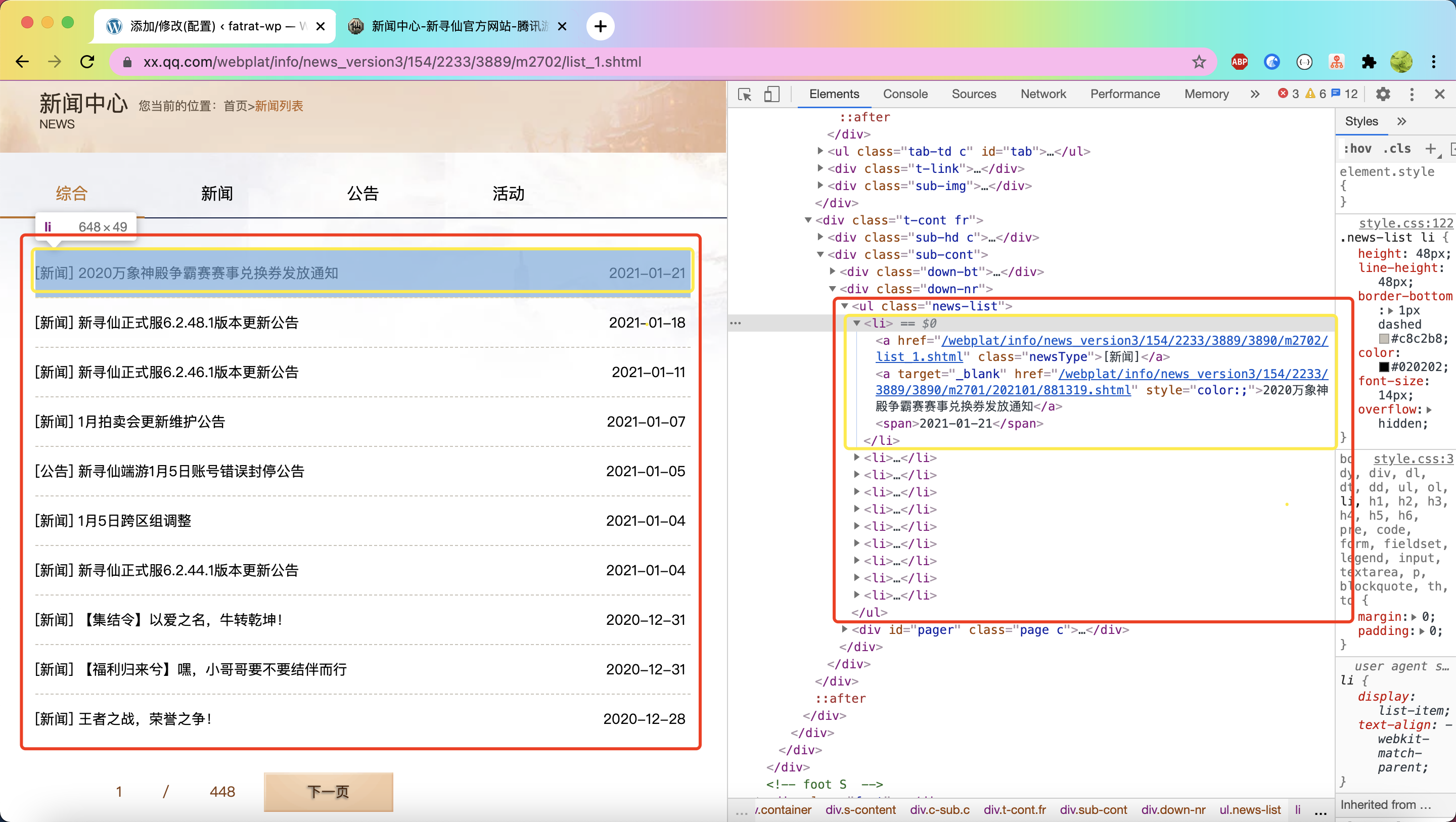
如图所画:他每页有十篇新闻
红色区域就是我们本页面所有文章所对应的数据区块,下面来采集这个区块
列表采集范围为 .down-nr>ul>li
解释:
我们使用规则 .down-nr 定位到 ul li 的外侧
再使用.down-nr>ul>li 可以定位到每一个li,这样就达到循环采集目的
范围选择错误可能只获取到一个数据
还能怎么写?
1 .down-nr li
2 .news-list>li
3 .news-list li
4 .sub-cont>.down-nr>ul>li
5 .sub-cont>.down-nr li
.....
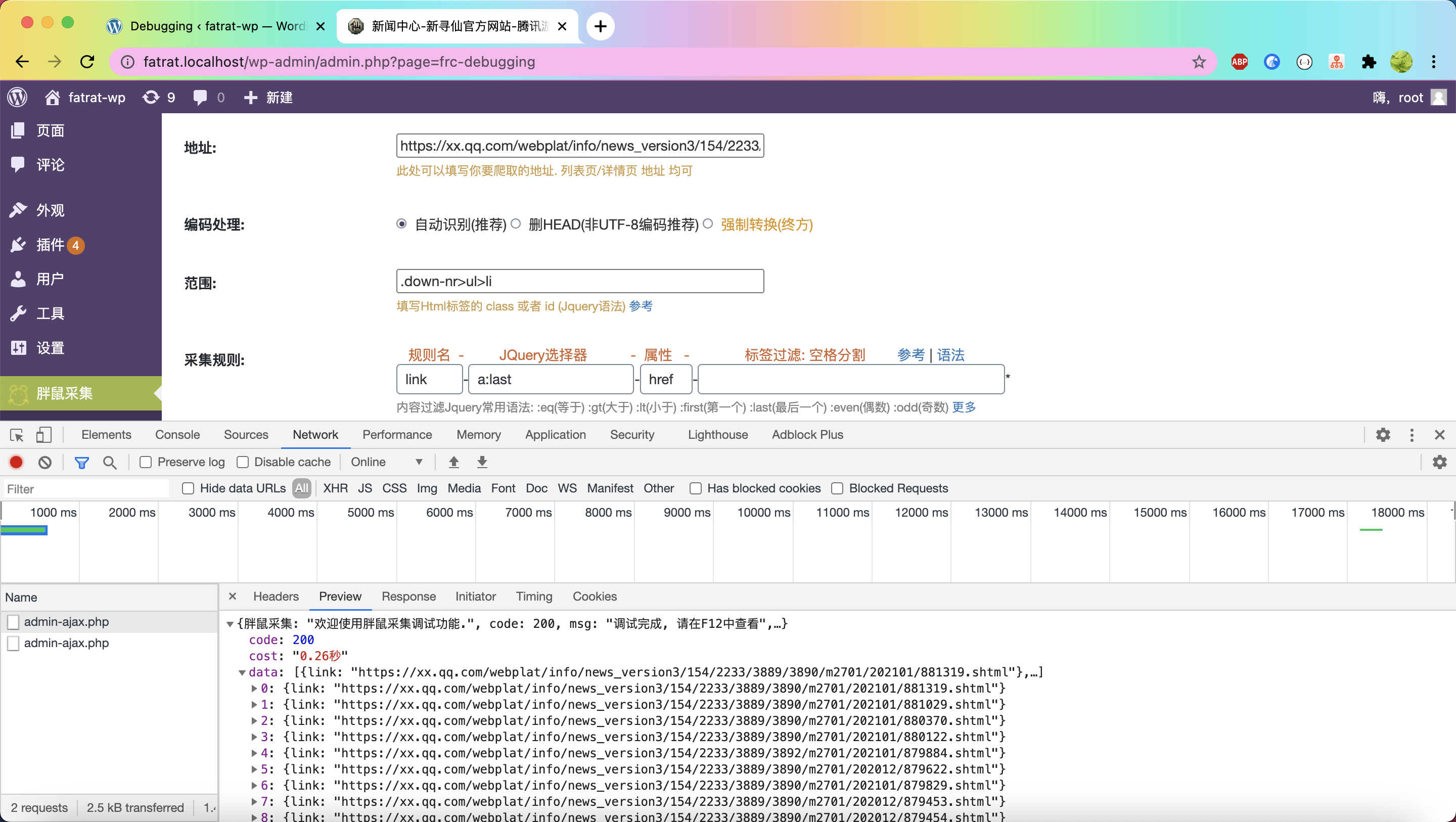
列表采集规则
link字段 Jquery选择器 = a:last 属性 = href
解释:
a 是选择a标签意思,但是他有两个a标签,第一个是分类列表页,第二个是我们想要的
:last 是选择最后一个
还能怎么写?
1 a:eq(1) eq等于的意思,程序从0开始
2 a[target="_blank"]
3 a[style="color:;"]
.....
{info} 写法很多,选择你喜欢的 要求能在Debug返回的结果中看到正确的数据
{info} 小提示规则范围定位的约小,采集时寻找页面的html dom节点越快
下面来采集详情页,第一步分析页面
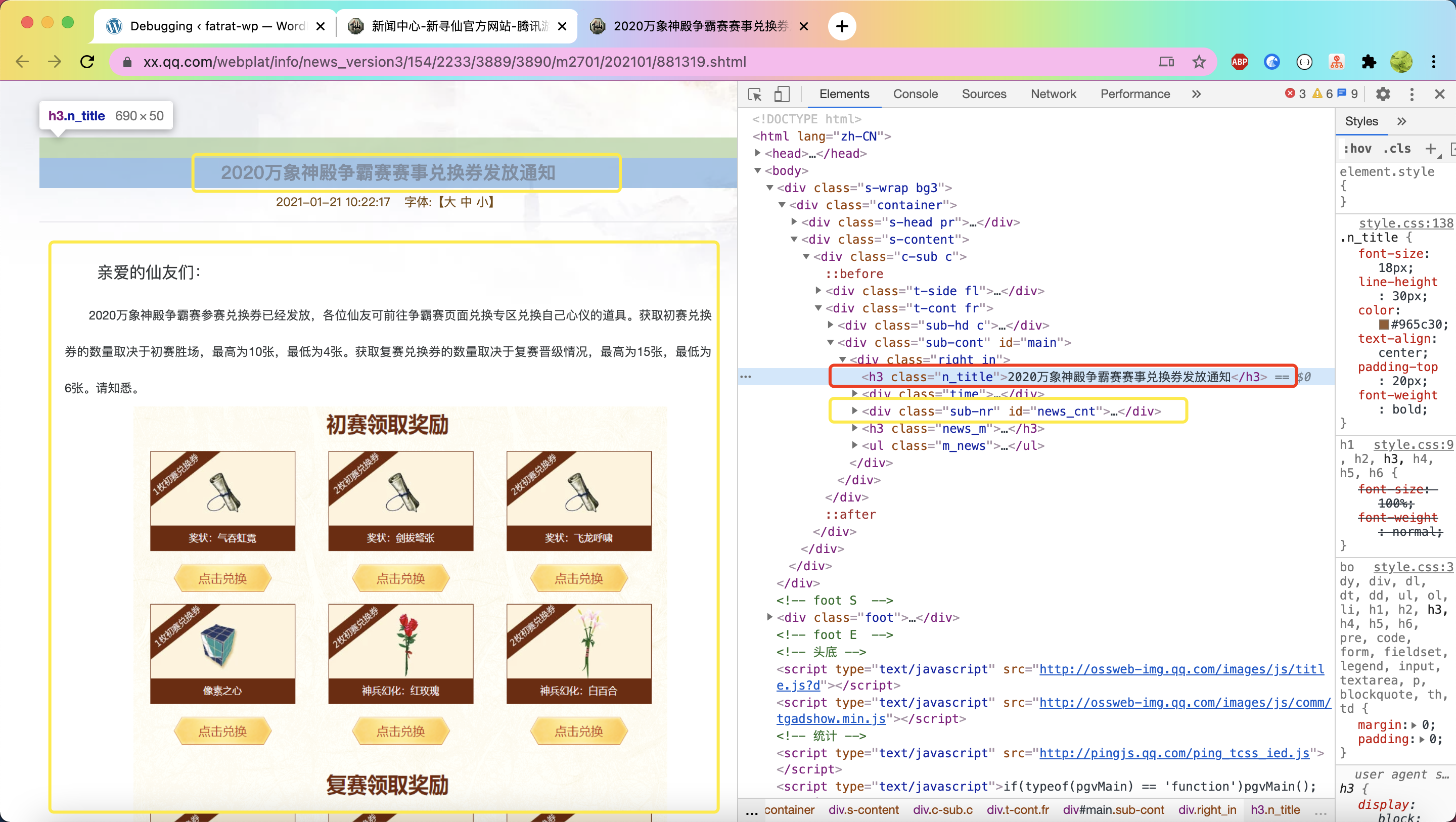

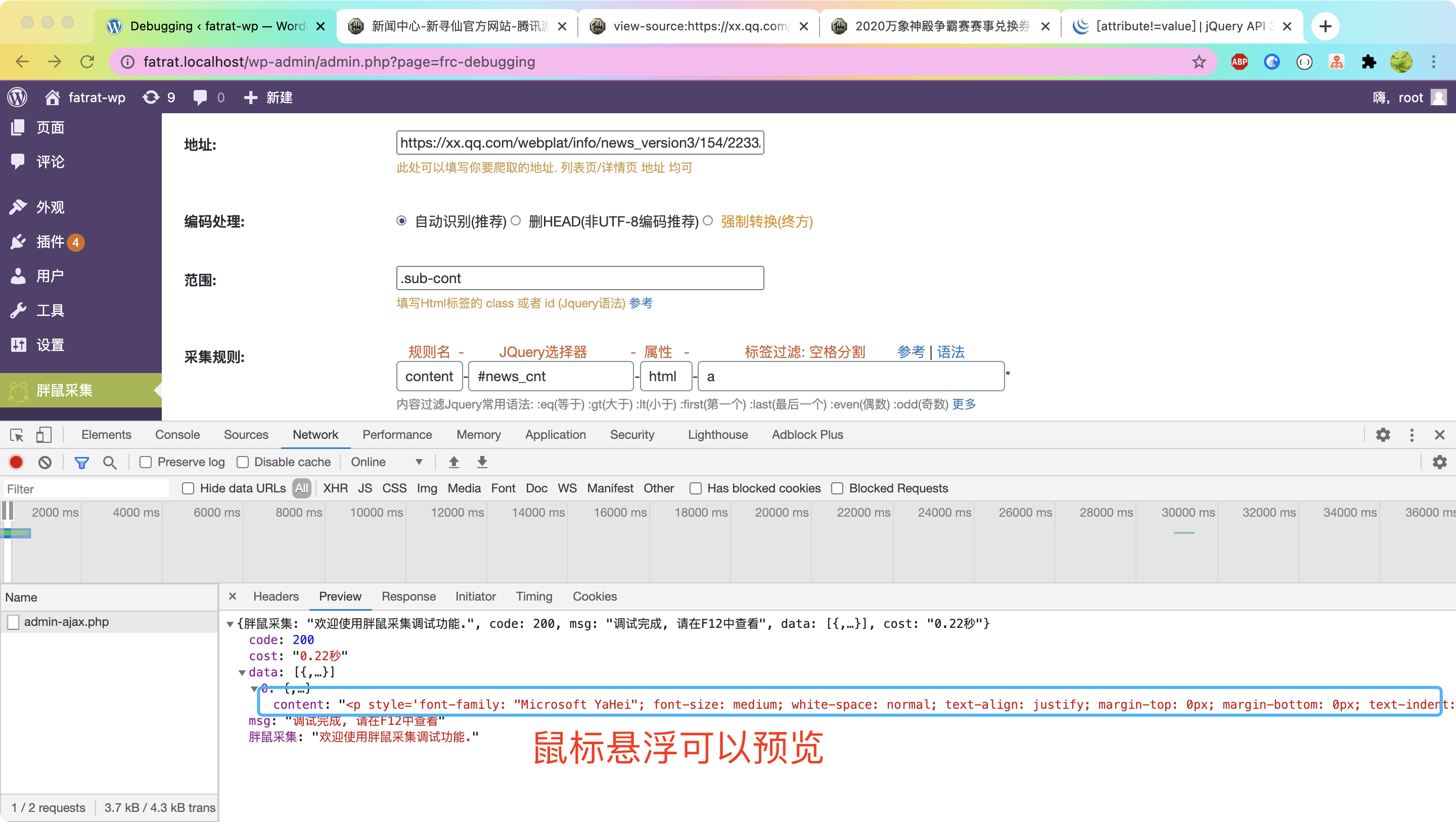
详情采集范围为 .sub-cont
解释:
因为他包括住了我们想要的 标题数据/内容数据
还能怎么写?
1 body 最大范围
2 .t-cont
3 #main
4 .right_in
.....
详情采集规则
title字段 Jquery选择器 = .n_title 属性 = text // 文本的意思
content字段 Jquery选择器 = #news_cnt 属性 = html // 顾名思义 内容没有html标签不好看
title字段还能怎么写?
1 h3
2 .right_in>h3
2 .right_in>.n_title
content字段还能怎么写?
1 .sub-nr
2 .right_in>.sub-nr
2 .right_in>#news_cnt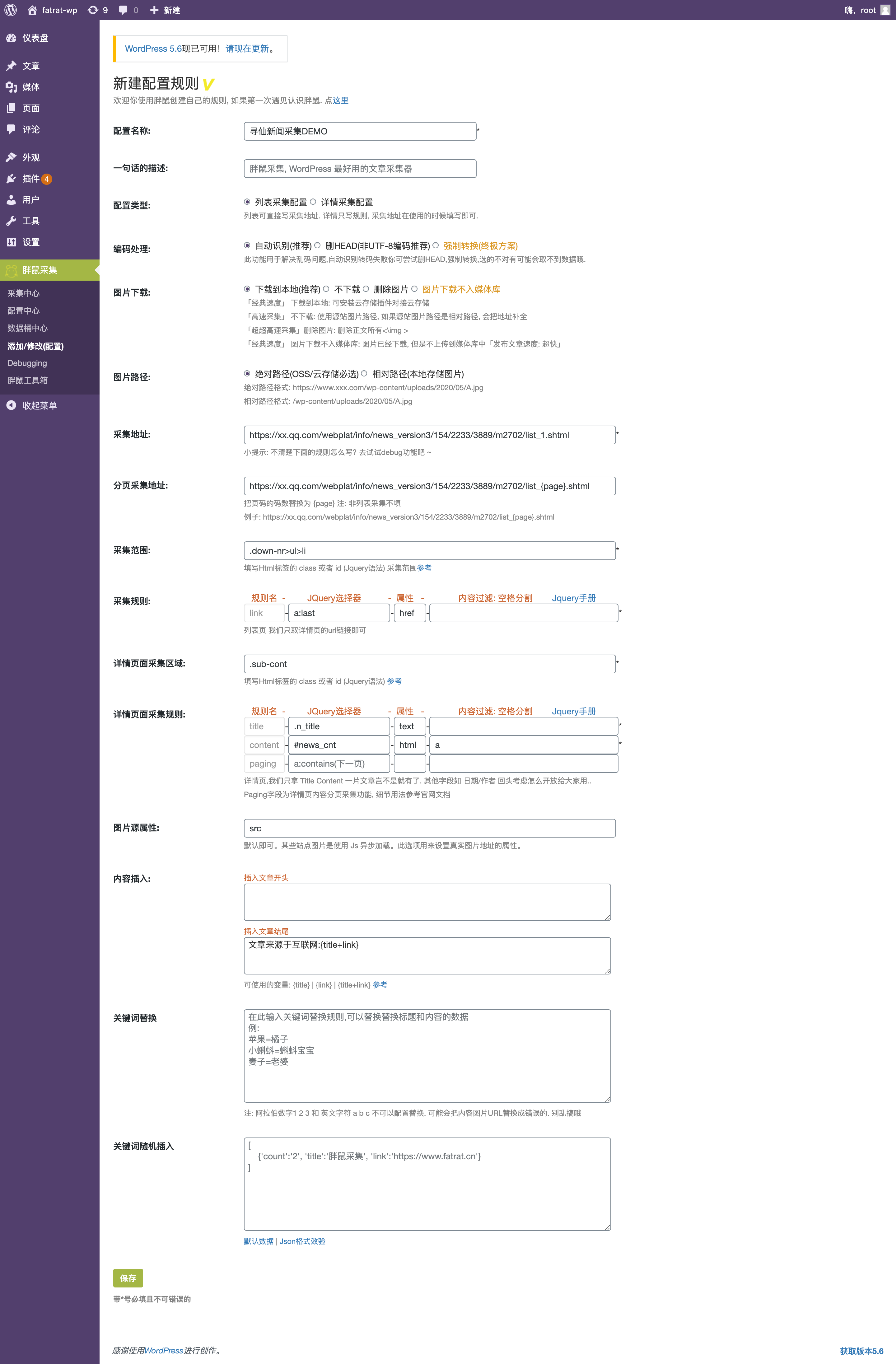
{info} 规则创建完成后,在采集中心点击采集按钮,默默等待提示成功即可
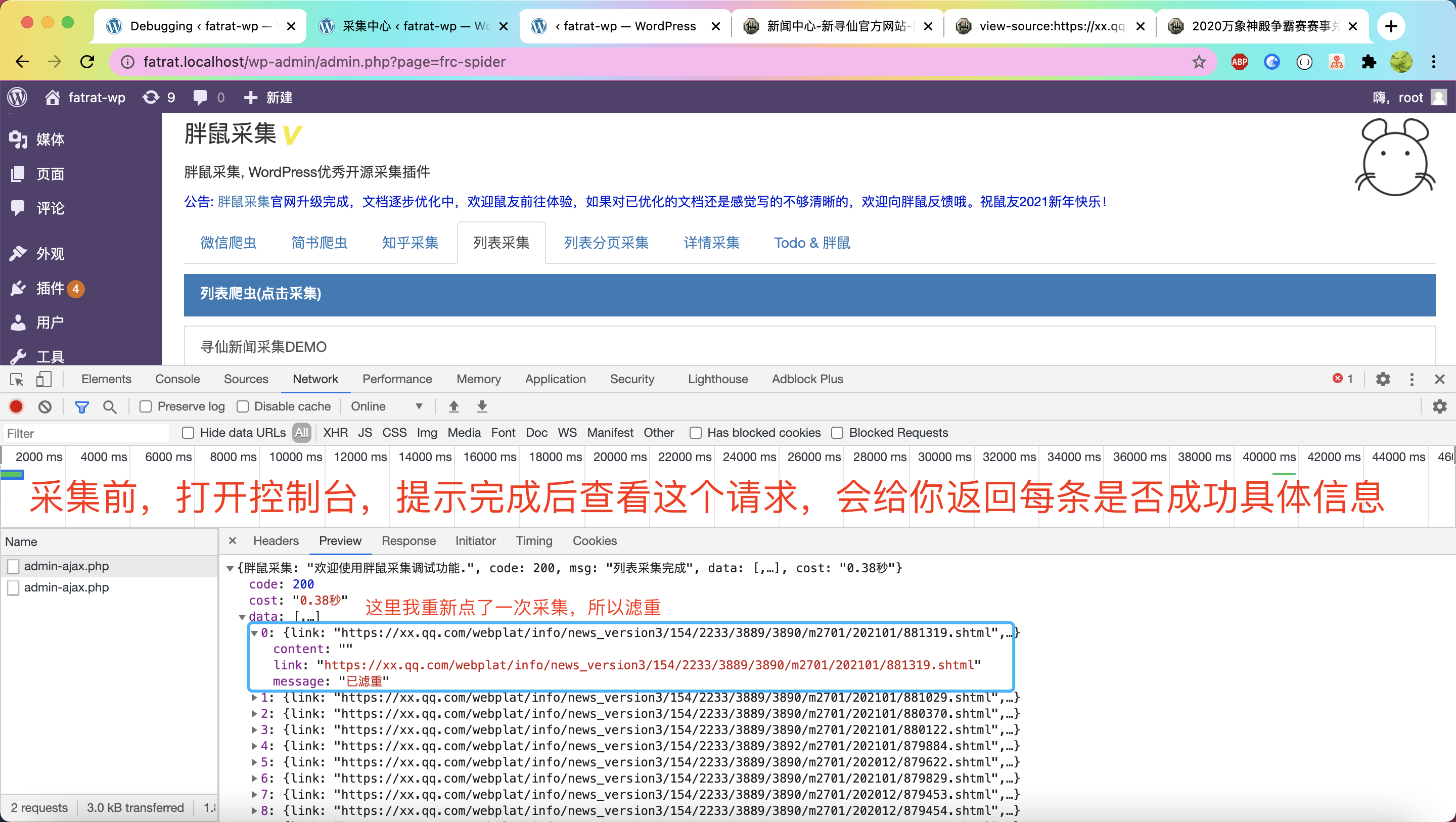
{success} Debug调试功能在每个页面都有返回哦,列表采集,历史分页采集,微信、简书、知乎、详情采集都有返回调试信息
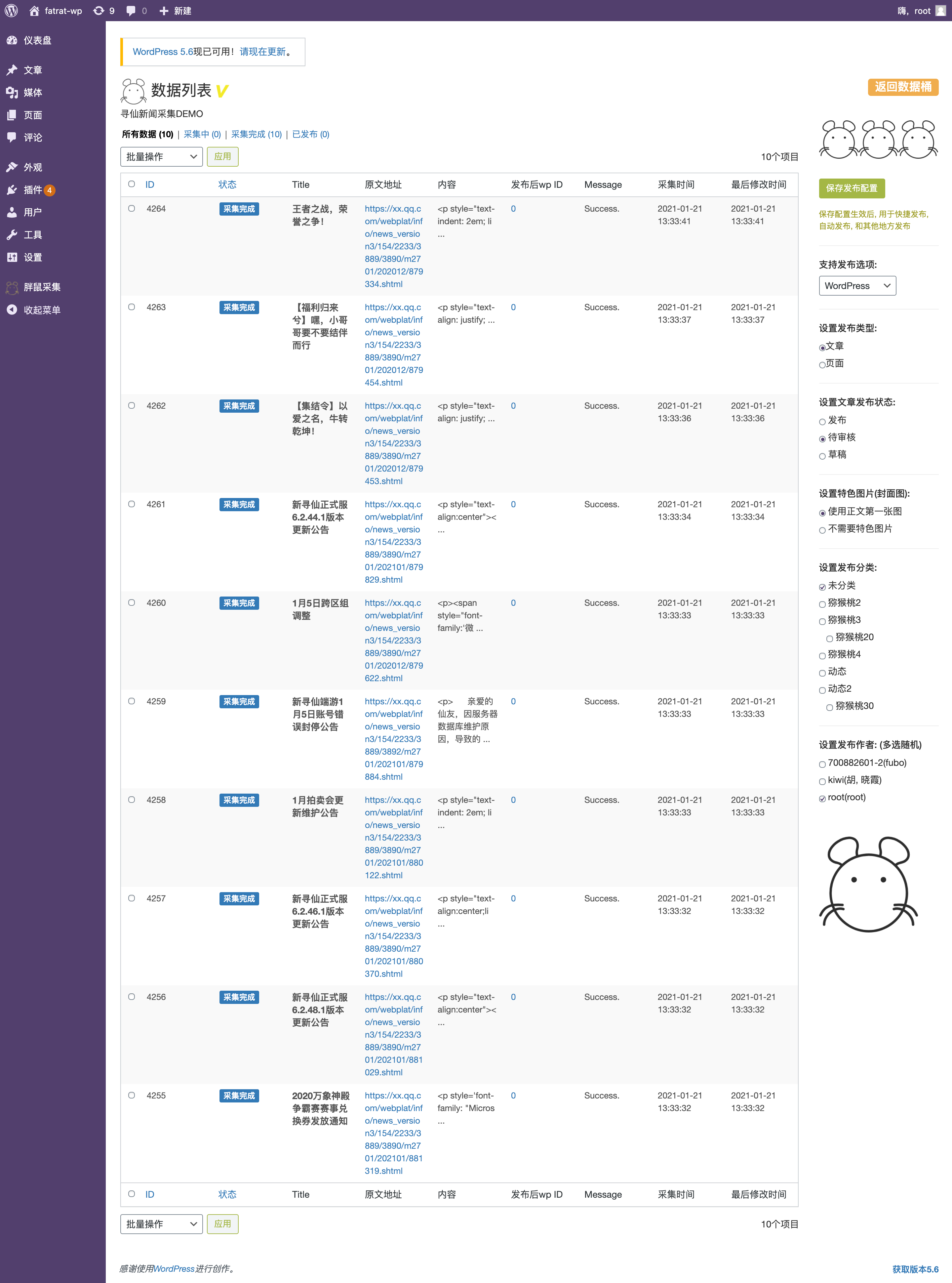
{primary} 还有什么疑惑来找胖鼠把,祝鼠友开心愉快!
内容过滤
内容过滤功能请移步 Go
列表分页采集
列表分页采集请移步 Go
代写规则
跟我来 Go
视频教程
胖鼠采集 - 新建规则(寻仙)视频教程地址 Go