Q&A(待完善)
{success} 在群内提问题。言简意赅。具体描述你所遇到的问题 + 合适的截图。
如何查看本次是否采集成功等信息重点
{info} 你是否遇到这样的问题?采集提示成功,数据桶没数据、不知道自己写的规则到底对不对

在点击采集按钮前,右键打开控制台 > 网络 > 点击采集 > 等待结果
调试信息会给到具体每条数据是否采集成功的详细信息,鼠友可以根据信息来判断
- 常见错误
文章在数据库已存在,滤重(滤重不区分规则,以详情页的url地址为准) // 有鼠友报告滤重不生效,仔细一看有可能是目标站重复了。同样的标题发两次,url地址不一样,胖鼠采集是不检测标题重复的内容错误: 是 title 或者 content 为空导致的。采集后入库这两个字段必须有值 // 一定要保证这两个字段有采集到的数据内容错误: 还有一冲情况。如果刚刚采集是正常的,过一会就发现内容错误、可能目标网站有防采集策略(当你批量采集时,速度较快,安全策略限制每分钟这个ip有多少次的请求等其他策略。超过了就办掉,给爬虫返回一下错误的html页面,所以取不到数据入库错误了)内容错误,如果debug正常,可能是目标站有拦截: 这个错误,一定要展开给你返回的调试信息,查看 title 字段 content 字段是否有数据,一般情况都是其中一个字段没有采集数据造成的。
网络超时/采集超时
- 采集的时候提示超时错误,因为采集需要 请求目标网站服务器 解析数据 下载图片 这些工作都十分耗费时间。在 php.ini 中缺省的最长执行时间是 30 秒,这是由 php.ini 中的 max_execution_time 变量指定,超过了就自动中断,网络超时。
- 加长php最大超时时间 (不推荐设置太长)
- 超时后,再次重新点击采集,已采集数据会自动滤重(推荐哦)
数据重复问题
目前采集的版本,都会全局滤重+数据库唯一索引。无需担心数据重复问题(同url一定不会重复)
注 v1 旧版本无法强滤重
图片相关
请先确定没有设置图片不本地化的选项
采集回来的图片是目标站的一张默认图,不是真实的图片
请查看目标站详情页,右键查看网页源代码,搜索 <img 查看目标站图片真实属性是什么,胖鼠下载图片默认是取在配置中心设置的图片真实地址的值,默认是src属性值、目标站图片懒加载网站真实的图片路径可能在data-src或者origin-src或者其他属性中,请根据图片地址真实的属性来陪配置中心设置
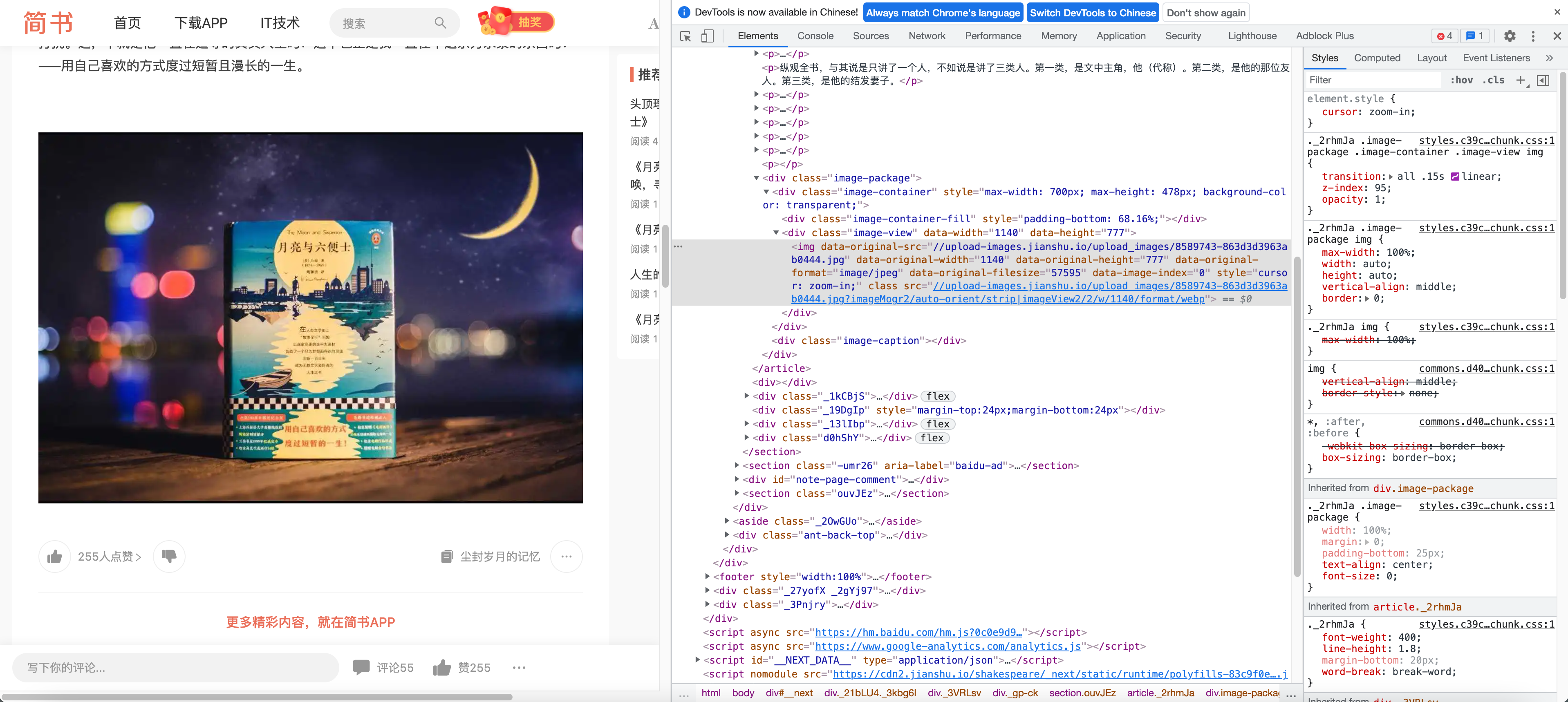
{info} 简书为例 真实的图片地址是 data-original-src
采集后图片有两个重复的
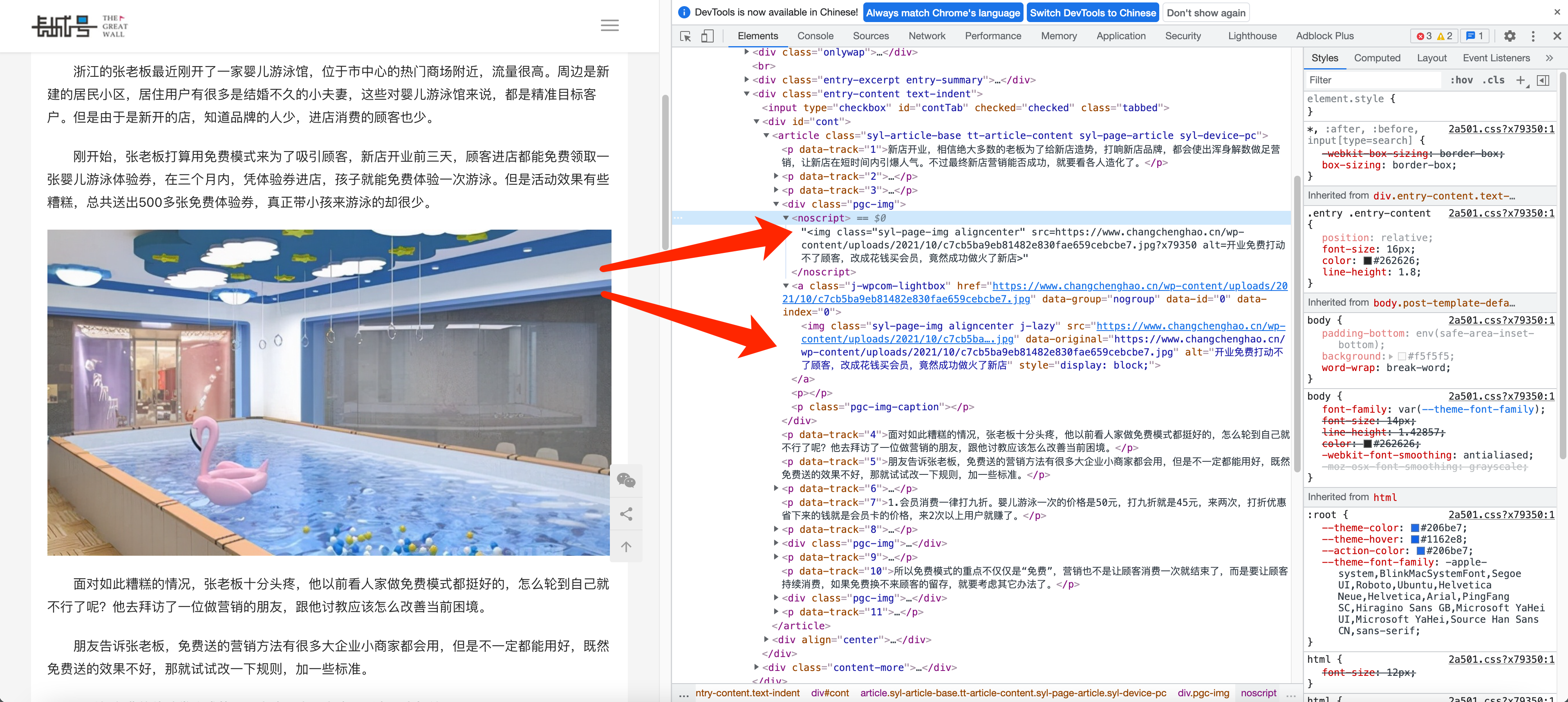
这个问题很多鼠友遇到过,不是采集bug 而是源站就是两张图片,只不过源站隐藏了。大家肉眼看不到而已。上图是例子
为什么要这样呢?
知识点 noscript 标签
介绍:"如果浏览器支持脚本,那么它不会显示出 noscript 元素中的文本。"
他是为了解决浏览器禁用 javascript, 但是又不想影响文章中图片的展示
解决方法标签过滤中增加 -noscript这样基本可以解决大家遇到99%的图片问题。
如果非上述问题还是不行。可以在服务器使用命令 curl 图片地址、看看 http状态 是否返回200,数据返回正常。有可能目标站把你的服务器ip禁止了
{primary} Tips: F12查看源代码是已经动态加载过的网页源代码。 右键查看网页源代码是未动态加载的,是我们需要的
文章采集后图片是源站链接?
图片采集失败,就会使用源站链接,或者你设置了不本地化图片。就这两种情况
采集被屏蔽如何检测。
在服务器上执行curl命令
curl -I https://www.baidu.com
返回:
HTTP/1.1 200 OK // 200为http成功状态码
Accept-Ranges: bytes
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Connection: keep-alive
Content-Length: 277
Content-Type: text/html
Date: Sun, 17 Jan 2021 14:42:24 GMT
Etag: "575e1f59-115"
Last-Modified: Mon, 13 Jun 2016 02:50:01 GMT
Pragma: no-cache
Server: bfe/1.0.8.18错误示范
curl -I https://www.baidu.com/aaaaa
HTTP/1.1 404 Not Found
Content-Type: text/html; charset=iso-8859-1
Date: Sun, 17 Jan 2021 14:45:06 GMT
Server: Apache查看给你返回的状态码是否正常即可注意是服务器不是本机
插件无法照顾所有鼠友面对目标站情况,没有办法越过复杂的防采集策略。实在不行就换个网站吧
{info} 善用文档快捷键的
/切换导航栏s搜索t滚动屏幕顶部b滚动屏幕底部
数据桶每页显示数量
计划在页面开发一个按钮 暂时可以在 网页url中追加参数 &snippets_per_page=100 可以调整每页显示数量
采集速度控制
平时采集速度太快容易被封,有些站点设置每分钟超过多少次就封ip,
控制采集速度可以在一定程度上解决此问题,目前没有开发图形界面上功能。可以修改源码
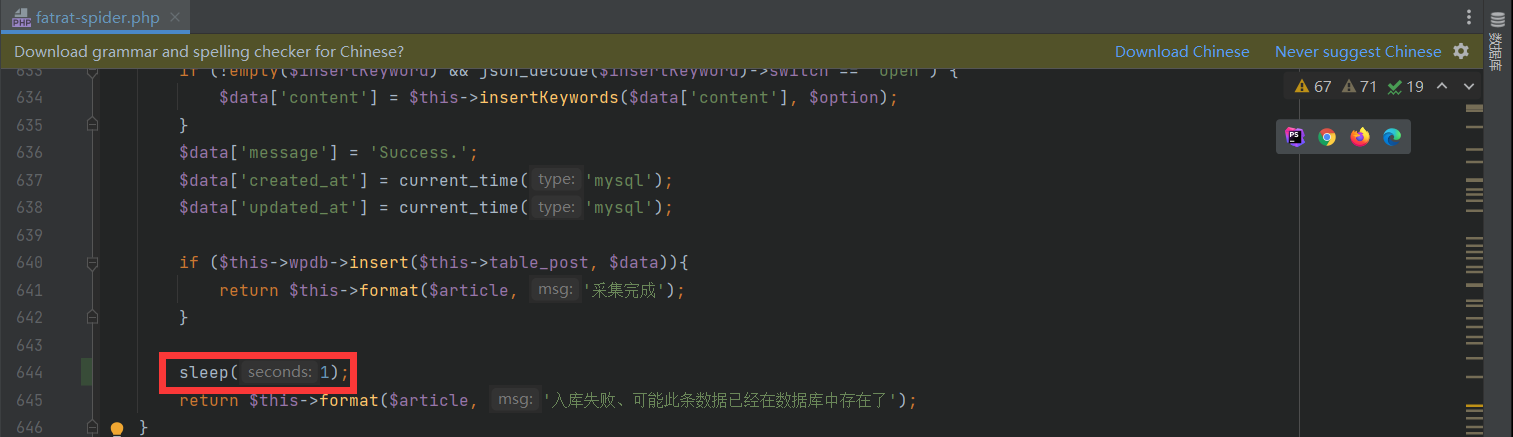
/wp-content/plugins/FatRat-Collect/includes/fatrat-spider.php 643行左右
增加延迟代码
sleep(2); 2代表秒、两秒内即可
可以解决一部分访问限速,非所有下载站下载地址替换
一些下载站,下载链接的a标签不会直接跳转。真实的url隐藏在标签属性中。导致我们采集过来也无法点击直接跳转。
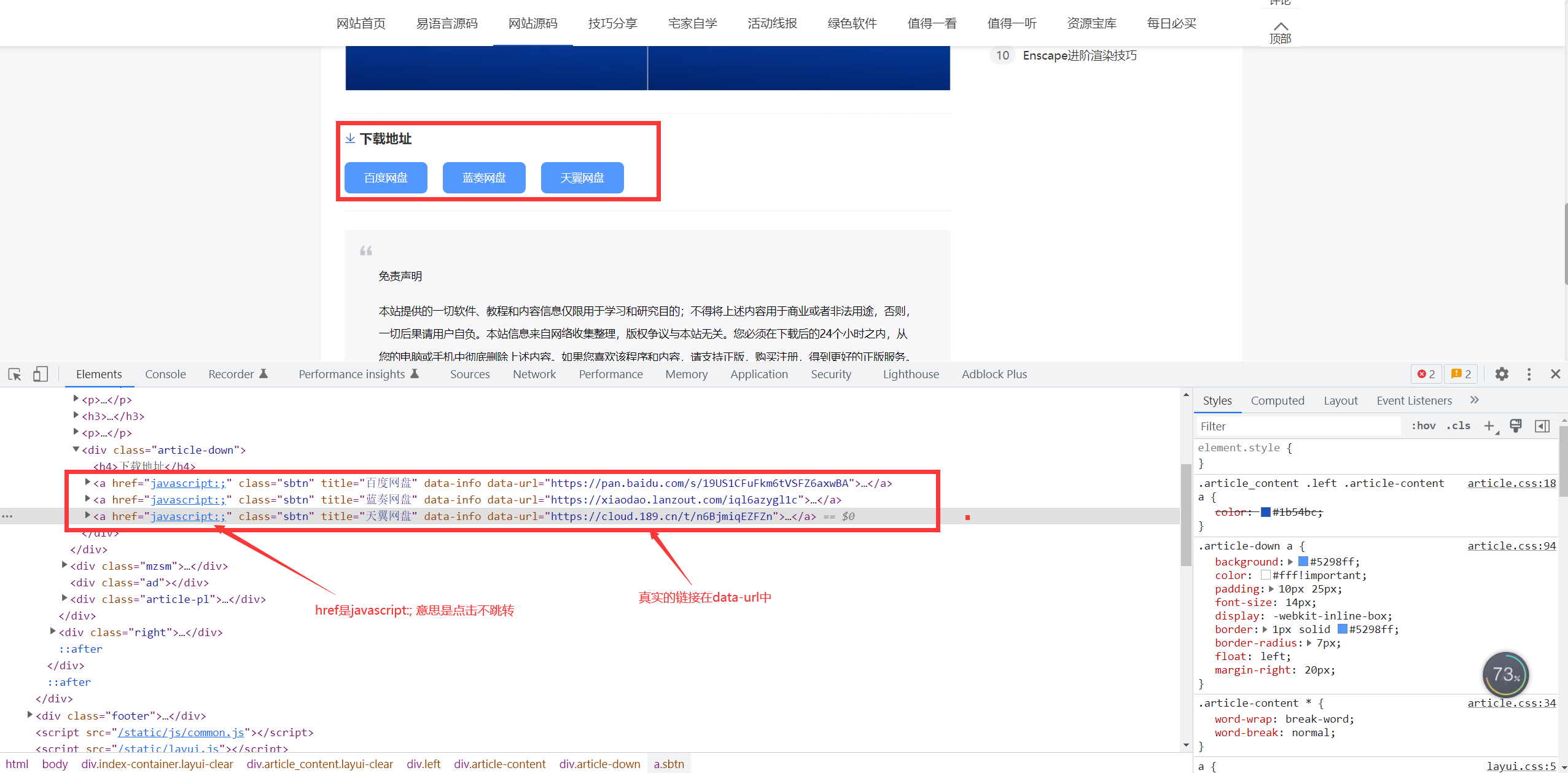 鼠友也可以通过修改源代码方式来解决一部分的问题。
鼠友也可以通过修改源代码方式来解决一部分的问题。

/wp-content/plugins/FatRat-Collect/includes/fatrat-spider.php 630行左右
$data['content'] = str_replace('href="https://xd.x6d.com/javascript:;"', '', $data['content']);
$data['content'] = str_replace('data-url', 'href', $data['content']);
这里要注意a标签href里面源站是javascript:;
胖鼠采集在前面的逻辑中会自动补全源站点的域名,所以上图就是完整域名啦
可以解决一部分下载站链接问题,非所有,根据此逻辑可自行调整
扩展知识
相同这里亦可以替换任何想修改的数据
$data['title']存储的是标题数据
$data['content']存储的是内容数据
例如:
title是 我爱我的家园
content是 今天天气真好啊
$data['title'] = $data['title'].'-胖鼠采集'; === 我爱我的家园-胖鼠采集
$data['content'] = str_replace('今天', '明天', $data['content']); === 明天天气真好啊
{primary} 没有一定基础知识建议不要修改。改之前复制一份fatrat-spider.php文件备份。改错了。覆盖还原
WordPress插件冲突问题
- 为什么会出现此问题
- 是因为其他插件和胖鼠采集插件都使用了composer,安装了第三方的依赖,两个插件相互依赖的包的版本不一致,wordpress只会加载其中一个版本,引发的问题。目前还没有看到成熟的解决方案
{primary} 推荐的做法是:换个其他的作者开发Oss或者云存储插件来试试
- 常见错误
- PHP Fatal error: Uncaught Error: Call to undefined method GuzzleHttp\Utils::chooseHandler()
- PHP Fatal error: Uncaught Error: Undefined class constant 'MAJOR_VERSION'
- 等使用了OSS插件或者其他插件造成可能冲突无法使用的情况
如有鼠友有技术能力,可根据错误来进行修复问题,在服务器使用命令行的方式安装 composer。
如你使用宝塔面板,可以在宝塔面板安装composer,或者其他手动安装方式:
Composer中国网站:https://pkg.xyz/#how-to-install-composer已知可修复的插件冲突:
1。PHP Fatal error: Uncaught Error: Call to undefined method GuzzleHttp\Utils::chooseHandler()
安装阿里云oss插件-OSS Aliyun 报错解决办法
cd 根目录/wp-content/plugins/oss-aliyun/sdk
composer require guzzlehttp/guzzle:^7.02。PHP Fatal error: Uncaught Error: Undefined class constant 'MAJOR_VERSION'
腾讯云oss插件-WPCOS(腾讯云对象存储) 或者更换插件 -- 腾讯云oss插件-Sync QCloud COS
cd 根目录/wp-content/plugins/wpcos/sdk/cos-php-sdk-v5
vim composer.json
输入以下代码:
{
"require": {
"guzzlehttp/guzzle": "^7.0"
}
}
保存后执行
composer require guzzlehttp/guzzle:^7.0